
The Thundering Herd Problem: Explained
Imagine you're standing outside Apple store on the release of it's new store. The doors are locked, and 1,000 people are huddled outside, all waiting for the same new IPhone 18 Pro Max. The moment those doors swing open, everyone rushes it at once, trampling the displays and overwhelming the 2 poor security guards at the front.
That's the Thundering Herd problem: a massive, synchronized surge of requests that crashes a system because everyone tried to access the same resource at the exact same moment.
What is the Thundering Herd Problem ?
In technical terms, it happens when a large number of processes or clients are waiting for an event (like a lock being released, or a cache being updated). When that event finally happens, all of them wake up and try to handle it simultaneously.
Instead of one person "fixing" the problem, everyone tries to fix it, which ends up breaking the system entirely.

Think of a standard web app setup:
-
The Goldilocks Zone: Usually, the App asks the Cache for data. The Cache has it, and the DB stays "chilling" and relaxed.
-
The Expiry: The data in the Cache has a "Time to Live (TTL)". Eventually, it expires.
-
The Stampede: If 10,000 users ask for that data, the millisecond after it expires, the Cache says "I don't have it!" to all 10,000 users. All 10,000 requests then "thunder" straight to your database to fetch the data.
Normal Spikes v/s Thundering Herds
Before moving forward with the actual system design, let us first go with the fundamentals of understanding the difference between normal spikes and thundering herds.
A Normal Spike is like a gold rush hour. You know more people are coming because it's 5:00 PM. You can prepare by adding more lanes.

A Thundering Herd is a "system-induced" spike. It's often caused by your owned code!

For example:
-
The IPL Example: A million people hit "Refresh" at the exact moment a match starts.
-
The Cache Expiry: You set your cache to expire every 10 minutes. At exactly 10:01, the system itself creates a massive hole that everyone falls into
In distributed systems, if one database gets crushed, or goes down, the "HERD" doesn't go away - it just moves to the next available server, knocking it down too. This is called Cascading Failure.
Quick Scenario Check: Imagine you run a site for concert tickets.

-
Scenario A: Users slowly trickle in over an hour.
-
Scenario B: You send a "Buy Now" push notification to 1 million users at once, and your cache for the "Ticket Price" expires at that exact second.
Consider another example:

Imagine you are the Lead Engineer for Netflix. A massive new season of Stranger Things is about to drop at exactly midnight. You have two situations:
-
Situation A: You have a "Coming Soon" page that updates every minute. At 11:59:59, the cache for that page expires for everyone at the same time.
-
Situation B: People are already on the site, browsing different categories (Horror, Comedy, Sci-Fi) throughout the evening.
Which will be a Thundering Herd Situation ? Obviously the situation A. The "event" that triggered the stampede was the Cache Expiry (TTL hitting zero) at 11:59:59. Because every single user was looking at the same page, and that page disappeared from the cache for everyone at once, they all rushed the database together.
The System Heart Attack
When that herd hits, it's not just "slow" - it can be fatal for your infrastructure. Here's what happens under the hood:
-
Database (DB): Imagine a librarian who can handle 10 people at a time. Suddenly, 10,000 people scream the same question at her. She trips, her glasses break, and she stops answering everyone. Similarly, the DB connection pool fills up, and it stops responding.
-
CPU: Your servers are sweating. They spend all their energy just trying to manage the "waiting line" (context switching) rather than actually fetching data.
-
Cache: Ironically, the cache stays empty as the DB is too busy to send it the update!
-
Latency: This is the "spinning wheel of death" for users. Requests that usually take 50ms now take 30 seconds... or just time out.
Why it's Dangerous in Distributed Systems
In a big system like Netflix, services depend on each other. If the "Movie Service", dies due Thundering Herd, the "Recommendation Service" might start failing too because it's waiting for the Movie Service. This is a Cascading Failure - one fallen domino knocks over the whole data centre.
The Fixes (How to Tame the Herd)
There are 3 main "weapons" we use here:
Request Coalescing (The "Group Order")

Imagine 100 people want a coffee. Instead of the barista making 100 individual trips to the kitchen for beans, the first person says, "Wait! Everyone wants the same thing, I'll go get the beans, and rest of you just wait here. "
The system only sends one request to the database. When the data comes back, it shares with all waiting user.
Cache Locking / Mutex
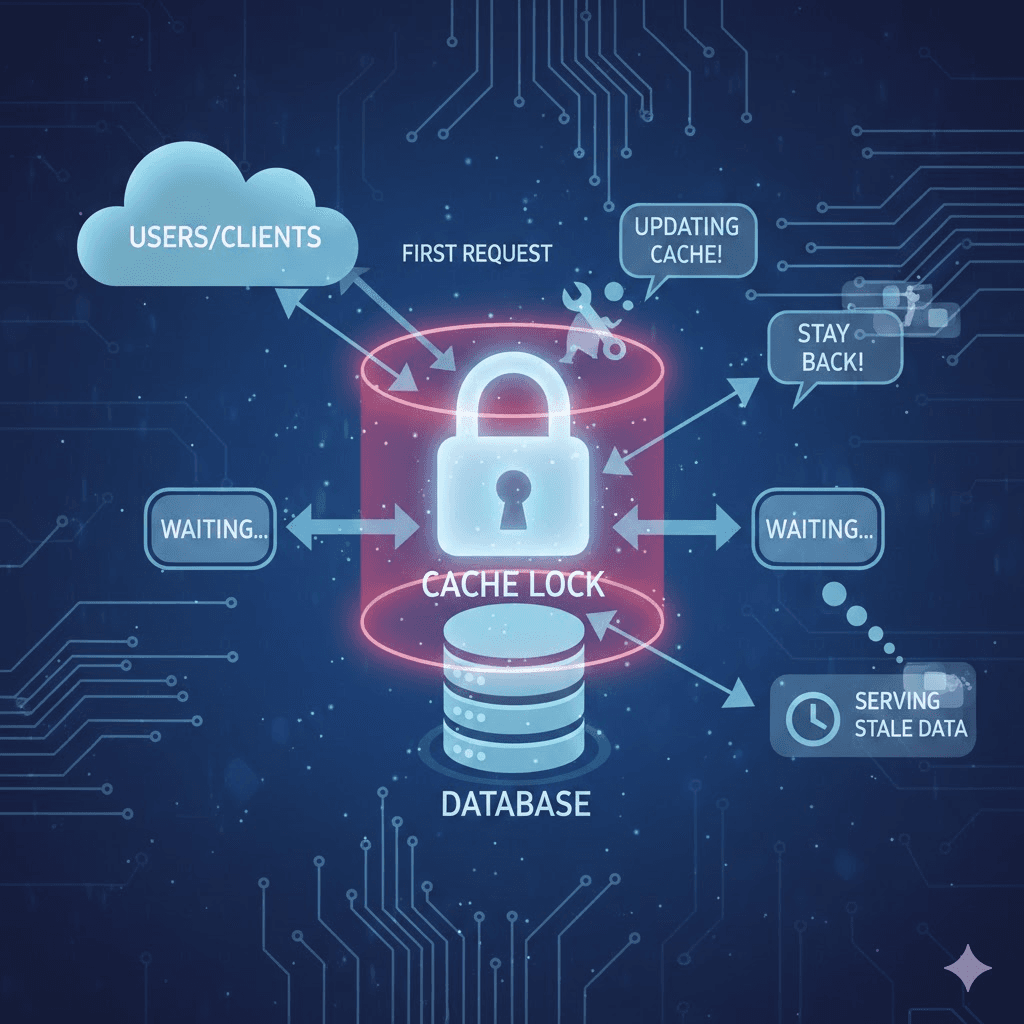
When the cache expires, the first request to arrive "grabs a lock". It tells the system, "I am currently updating the cache! Nobody else go to the Database." Other requests see the lock and either wait or server slightly "stale" (old) data for a few more seconds.
Staggered Expiry (Adding "Jitter")

This is a clever one. Instead of setting every cache to expire in exactly 600 seconds, you add a bit of randomness:
-
User A's cache expires in 600s.
-
User B's cache expires in 605s.
-
User C's cache expires in 597s.
This spreads the "thunder" out over several seconds so it sounds more like a gentle rain.
Exponential Backoff
If a request fails (because the herd already knocked the server down), don't let the client try again immediately! If 1,000,000 apps all retry at the exact same second, they just knock the server down again.
The Fix: Each time a request fails, the client waits a bit longer before trying again (1s, then 2s, then 4s, then 8s...). It gives the "Librarian" time to stand back up.