Deep Dive into Vector Databases and Indexing
In the middle of AI Revolution, it is for sure that any industry it touches, it promises great innovations but also introduces new challenges. It is very important to have efficient data processing for all applications which involves Large Language Models, Generative AI & Semantic Search.
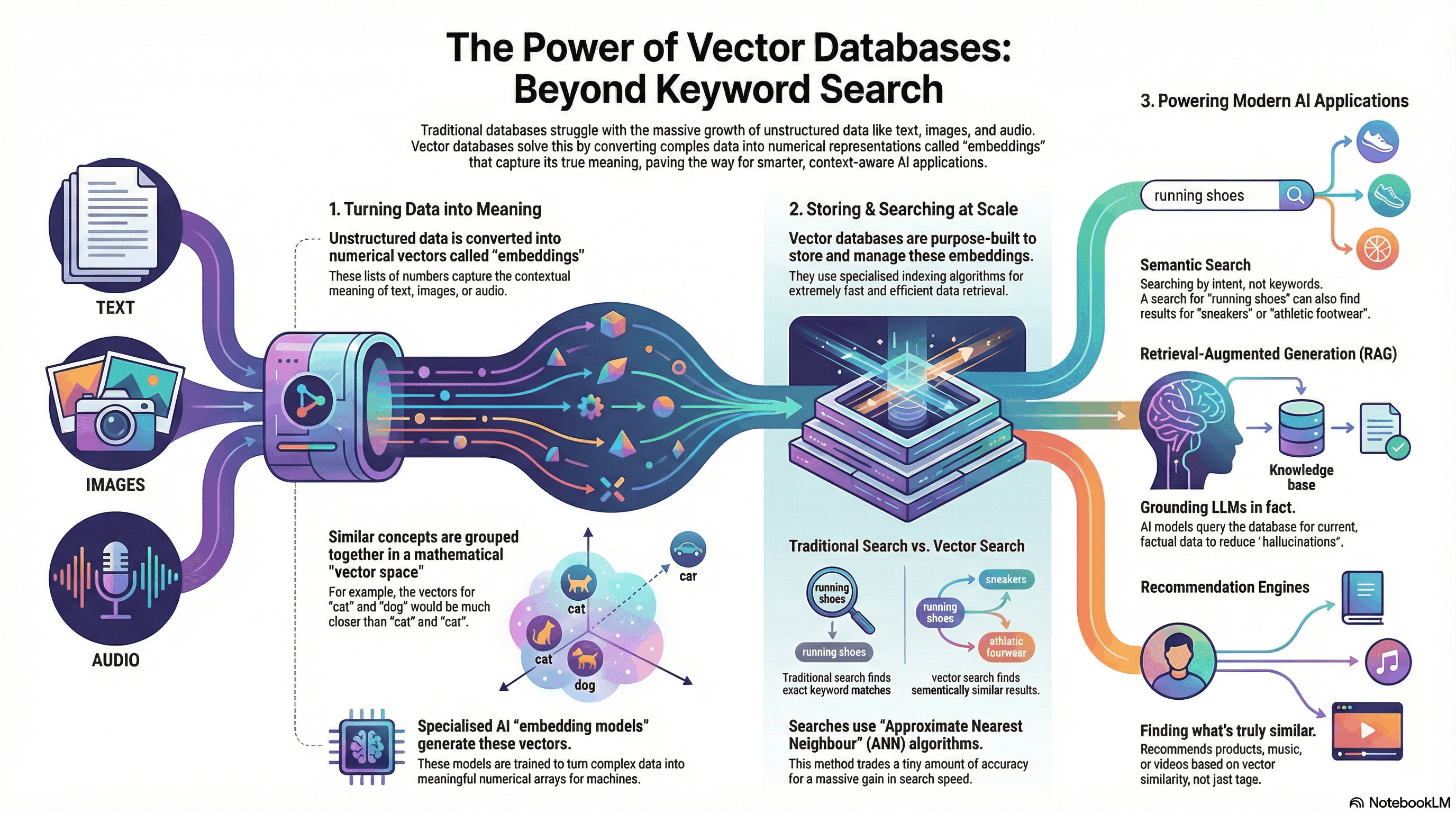
All of the applications rely on vector embeddings, which are a type of vector data representation that carries semantic information that is critical for AI to gain understanding and maintain a long-term memory they can draw upon executing complex tasks. Embeddings are generated by the LLMs and have many features, making their representation challenging to manage. These features represent different dimensions of data that are essential for understanding patterns, relationships and underlying structures.
This requires specialized database designed specifically for handling this data type. Vector Databases have the capabilities of traditional database that are absent in standalone vector indexes and the specialization of dealing with vector embeddings, which the traditional databases lack. These vector databases are intentionally designed to handle complex data and offer performance, scalability and flexibility you need to make the most out of your data. With a vector database, we as a developer can add our knowledge to our AIs, like semantic information retrieval, long-term memory and more**.**

How does a Vector Database Work ?
The traditional approach for database is that they store strings, numbers and other types of scaler data in rows and columns. Vector databases on the other hand operates on Vectors, so the way it is optimised and queried is quite different. In our traditional databases, we usually query for rows in the database where the value exactly matches our query, whereas in vector databases, we apply a similarity metric to find out a vector that is the most similar to our query.
In a vector database, there are combinations of different algorithms that participate in ANN Search Algorithm which is basically a technique to quickly find data points in large, high-dimensional datasets that are similar to a given query point, prioritizing speed and scalability over find single absolute closest match.
These algorithms are assembled into a pipeline that provides fast and accurate retrieval of neighbours of a queried vector. Below is a common pipeline:

-
Indexing: Indexing is about intelligently organising vector embeddings to optimise the retrieval process. It involves advanced algorithms to nearly arrange the high dimensional vectors in searchable and efficient manner. Some of the common techniques are Inverted File (IVF), Hierarchical Navigable Small World Algorithms (HNSW), Multi-Scale Tree Graph Algorithm (MSTG).
-
Querying: The vector database now compares the indexed query vector to indexed vectors in dataset to find the nearest neighbours.
-
Post Processing: Some cases where the vector database retrieves the final nearest neighbours from dataset, it then post-processes them to return the final results. This step can include reranking the nearest neighbours using a different similarity measure.
What are Vectors ?
Before moving forward, let us first get into the fundamentals first. Let us first understand what are Vectors. A vector is essentially a list (or array) of numbers that represents data. Think of a vector as a coordinate system for meaning.
Scalar vs. Vector: A "scalar" is a single number (e.g., today's temperature is 85°F). A "vector" is a collection of numbers describing a complex object (e.g., today's weather is representing the low, mean, and high temperatures)
Vector numbers can represent complex objects such as words, images, videos and audio generated by an ML model. This high-dimensional vector data, containing multiple features, is essential to machine learning, natural language processing (NLP) and other AI tasks.
What are Vector Embeddings ?
Now that we know what are vectors, let us now understand what are vector embeddings. Vector Embeddings are numerical representations of data points that converts various types of data including non-mathematical data such as words, audio or images - into array of numbers that ML models can process. Vector embedding is a way to convert an unstructured data point into an array of numbers that expresses that data’s original meaning.
Consider the example:
cat = [ 0.5, -0.7, 0.9]
dog = [0.9, 0.2, 0.9]
Here, each word is associated with a unique vector. The values in the vector represent the word’s position in a continuous 3-dimensional vector space. Embedding models are trained to convert data points into vectors. Vector databases store and index the outputs of these embedding models.
Summing up, this is how the vectors are displayed on a x-y-z scale:

Vector Indexing
Vectors created need to be indexed to accelerate searches within high-dimensional data spaces. Vector databases create indexes on vector embeddings for search functions. Indexing maps the vectors to new data structures that enables faster similarity such as nearest neighbor searches, between vectors. Vector can be indexed by using algorithms such as Hierarchical Navigable Small World (HNSW), Locality-Sensitive Hashing (LSH) or Product Quantization (PQ)
Semantic Search
Traditional search engines typically focus on matching keywords within a search query to corresponding keywords in indexed web pages. Semantic search is a data searching technique that focuses on understanding the contextual meaning and intent behind a user’s search query, rather than only matching keywords. Imagine searching for "best laptops for graphic design students." A traditional search engine might focus solely on matching those keywords to web pages. Whereas, a semantic search engine would try to understand that you are looking for laptops with specific features like powerful graphics cards, ample RAM, and color-accurate displays. Then it would return the results that would recommend laptops for graphic design related tasks.
Here’s how it works:
Semantic search engines employ various techniques from natural language processing (NLP), knowledge representation, and machine learning to understand the semantics of search queries and web content. Here's a breakdown of the process:
-
Query analysis: The search engine analyzes the user's query to identify keywords, phrases, and entities. It also attempts to interpret the user's search intent by analyzing the relationships between these elements.
-
Knowledge graph integration: Semantic search engines often leverage knowledge graphs, vast databases containing information about entities and their relationships. This information helps the engine understand the context of the search query.
-
Content analysis: Similar to how a search engine analyzes queries, it also examines the content of web pages to determine their relevance to a particular search. This analysis goes beyond keyword matching and considers factors such as the overall topic, sentiment, and entities mentioned within the content.
-
Result return and retrieval: Based on the analysis of the query and the content, the search engine could return web pages according to their relevance and semantic similarity to the search query. It then retrieves and displays the most relevant results to the user.
Use the links given below to understand more about vector databases: